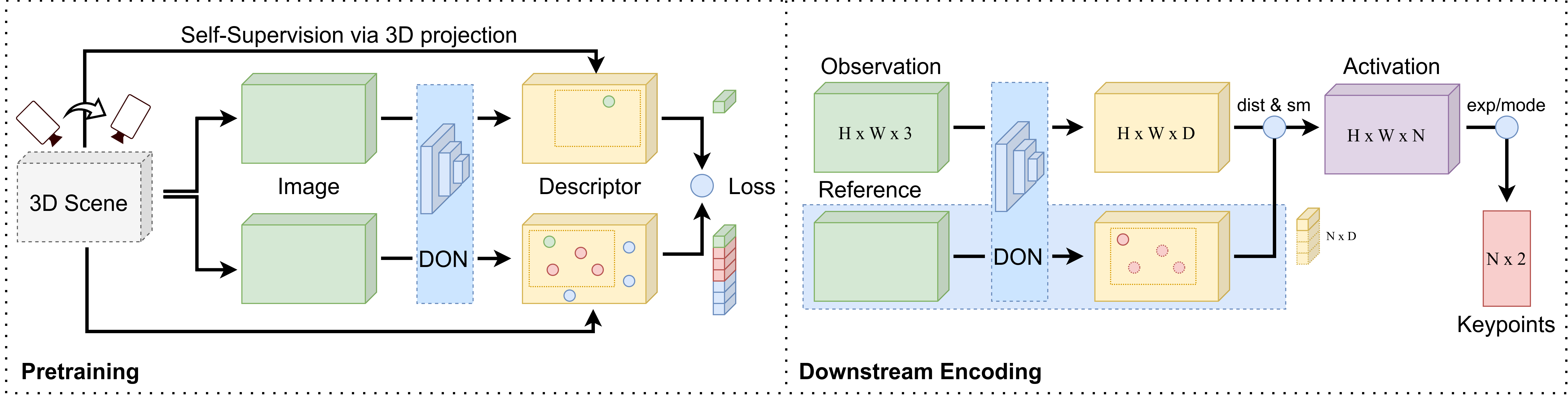
In policy learning for robotic manipulation, sample efficiency is of paramount importance. Thus, learning and extracting more compact representations from camera observations is a promising avenue. However, current methods often assume full observability of the scene and struggle with scale invariance. In many tasks and settings, this assumption does not hold as objects in the scene are often occluded or lie outside the field of view of the camera, rendering the camera observation ambiguous with regard to their location. To tackle this problem, we present BASK, a Bayesian approach to tracking scale-invariant keypoints over time. Our approach can successfully resolve inherent ambiguities in images, enabling keypoint tracking on symmetrical objects and occluded and out-of-view objects. We employ our method to learn challenging multi-object robot manipulation tasks from wrist camera observations and demonstrate superior utility for policy learning compared to other representation learning techniques. Furthermore, we show outstanding robustness towards disturbances such as clutter, occlusions, and noisy depth measurements, as well as generalization to unseen objects both in simulation and real-world robotic experiments.
The Treachery of Images: Bayesian Scene Keypoints for Deep Policy Learning in Robotic Manipulation
Jan Ole von Hartz, Eugenio Chisari, Tim Welschehold, Wolfram Burgard, Joschka Boedecker, and Abhinav Valada